İlk mövzuda Maşın Öyrənməsi alqoritmlərindən, öyrənmə prosesi və prediction zamanı istifadə etməli olduğumuz verilən tiplərindən (train, validation, test) danışdıq. Bu mövzumuzda isə daha çox verilənlər strukturunu anlamağa çalışacağıq. Müxtəlif növ verilənlər mövcuddur: matriks, qraf, video, səs, şəkil və s. Həll etmək istədiyimiz problemdən aslı olaraq fərqli verilənlərlə işləyə bilərik.
Matriks
Səs
Verilənlər obyektlərdən(objects) və atributlardan(attributes) ibarətdir. Məsələn, verilənlər bazasında cədvəllər sətir (row) və sütunlardan (columns) təşkil olunur. Ümumilikdə isə sətirlər->obyektlər, sütunlar->atributlar kimi düşünə bilərik. Obyekt və atribut anlayışları üçün ekvivalent hesab olunan terminlər də mövcuddur.
Obyektlər(objects) – samples, examples, instances, data points, observations.
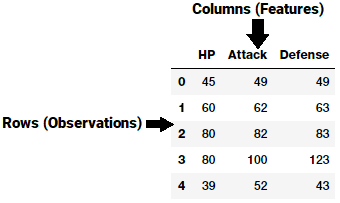
Maşın öyrənməsi alqoritmləri əsasən iki ölçülü verilənlərlə işləyir. Hər bir obyekt (object/observation) atributlardan (attributes/features) təşkil olunmuş vektordur. Bütün obyektlər isə birlikdə iki ölçülü matriks əmələ gətirir. Aşağıdakı şəkildə 5 obyekt və 3 atributdan (HP, Attack, Defense) ibarət nümunə verilmişdir. Məsələn, 0-cı obyekt (HP=45, Attack=49, Defense=49) vektorunu özündə saxlayır.
Baxdığımız nümünədə atributlar (HP, Attack, Defense) yalnız ədədi dəyərlər (numeric values) alır. Ümumilikdə isə atributların iki növü vardır:
Ədədi (Numeric)
Kateqorik (Categorical)
Ədədi dəyərlər sayıla bilən, üstündə riyazi əməliyyatlar apara biləcəyimiz dəyərlərdir. Məsələn, insanın yaşı, boyu, əmək haqqı miqadarı və s.
Kateqorik dəyərlər isə daha çox obyektin xüsusiyyətlərini təsvir edə biləcəyimiz dəyərlərdir. Məsələn, insan cinsi, qan qrupu, yaşadığı şəhər adı, evlilik statusu və s. Bəzən kateqorik dəyərlər də ədədlər şəklində təsvir oluna bilər. Buna kodlaşdırma kimi baxa bilərik. Məsələn, insan cinsi kişi və qadın kimi yox 0 və 1 kimi də təsvir edə bilərik. Amma kateqorik dəyərlər üzərində riyazi əməliyyatlar aparmağımız mümkün deyil.
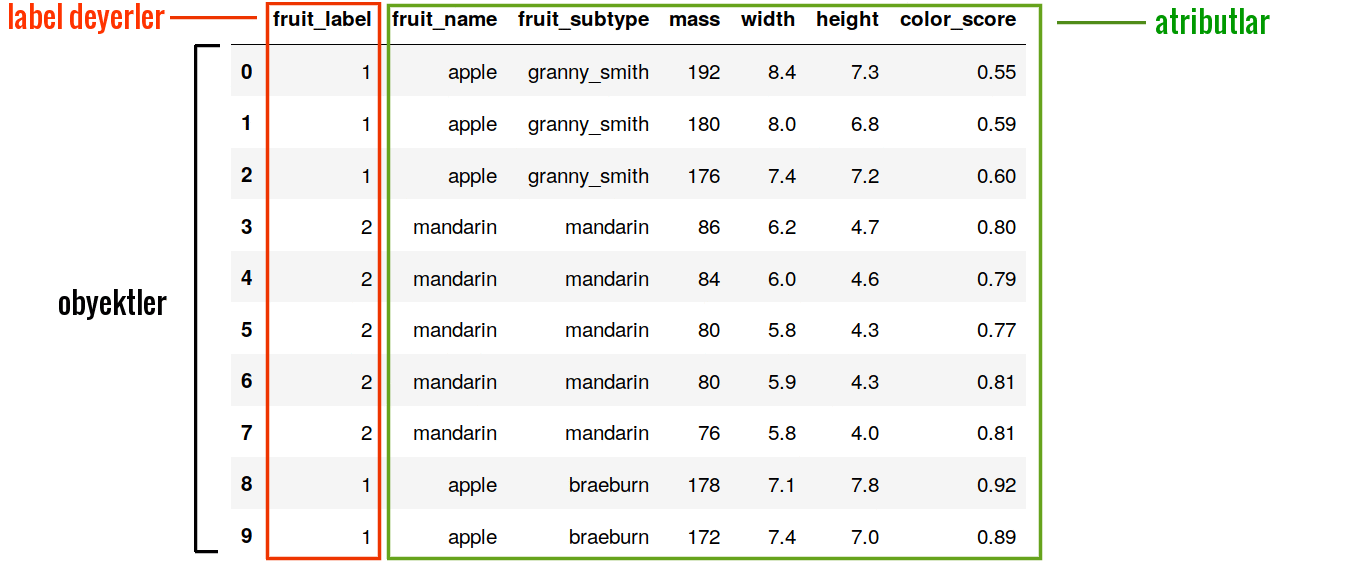
İndi isə müəyyən bir verilənlər üzərində python 3 ‘dən istifadə edərək öyrəndiyimiz anlayışları daha dərindən başa düşək. Nümunə verilənlər kimi “fruits dataset” nə baxaq. Dataset’i bu linkdən yükləyə bilərik. İlk 10 sətir aşağıdakı şəkildədir. Dataset meyvələrin adından (fruit_name), növündən (fruit_subtype), kütləsindən (mass), ölçülərindən (width, height) və rəng dəyərindən (color_score) aslı olaraq hansı sinifə (fruit_label) aid olmasını təsvir edir.
Python da əsasən pandas, numpy, scikit-learn kitabxanaları ilə, mühit olaraq Jupyter Notebook işləyəcəyik. Bu mövzumuz üçün notebook faylını burdan yükləyə bilər və praktiki olaraq işləyə bilərsiz.
Machine Learning sistemlərə əvvəlki təcrübələr əsasında öyrənməyi və inkişaf etdirməyi təmin edən Artificial İntelligence-in (Aİ) (Süni İntellekt) əsas hissəsidir. Machine Learning’in çalışma mexanizmi ondan ibarətdir ki, ilk öncə Machine Learning alqoritmləri training data (verilmiş data) üzərində riyazi modeli qurur və bu modeldən istifadə edərək test data üçün mümkün ola biləcək ən yüksək ehtimallı nəticəni predict (təxmin etmək) edir. İndi isə Machine Learning zamanı istifadə olunan data növlərini oyrənək.
Training data
Training data: Modelin öyrədildiyi zaman istifadə olunan datadır. Bu process training prosesi adlanır. Training müddətində riyazi model istifadə etdiyi parametrlər üçün dəyərlər təyin edir.
Validation data
Validation data: Modelin nə dərəcədə yaxşı train olunduğunu qiymətləndirir. Validation data modelin performansını artırmaq, training zamanı öyrənilən parametr dəyərlərini inkişaf etdirmək üçün istifadə olunur.
Test data
Test data: Modelin performansı validation zamanı təkminləşdirilmiş parametrlərdən istifadə edərək test data üzərində təyin edilir. Test data müxtəlif modellər arasında seçim etməyə komək edir. Belə ki, testing zamanı ən yaxşı nəticəni göstərən model real olaraq yeni data üzərində prediction edilməsi üçün tətbiq edilir.
İndi isə training, validation və test datanın nə olduğunu bildiyimiz üçün, bu dataların hansı nisbətdə bölünməsindən danışa bilərik. Öyrənilmə prosesi training data üzərində getdiyi görə, training datanın ölçüsünün mümkün qədər böyük olması lazımdır. Buna görə, adətən, ilk olaraq verilmiş datadantraining və test data 80-20% nisbətində ayrılır. Əldə olunmuş training datadan isə yeni training və validation data 80-20% nisbətində ayrılır. Aşağıdakı şəkildə bu proses vizual olaraq təsvir edilib.
Machine Learning Alqoritmləri
Machine Learning Alqoritmləri aşağıdakı kateqoriyalara bölünür:
Supervised Learning
Unsupervised Learning
Semi-supervised Learning
Reinforcement Learning
Supervised və Unsupervised Learning alqoritmləri haqqında danışmazdan əvvəl labeled və unlabeled data haqqında məlumat vermək istərdim. Belə ki, bu iki alqoritmi fərqli edən istifadə edilən data növüdür. Labeled data o deməkdir ki, modelin training data əsasında hansı dəyərləri təxmin (predict) edəcəyi haqqında məlumatımız var. Məsələn, nümunə olaraq göstərə bilərik ki, əlimizdə olan training data yalnız pişik və it haqqında məlumat saxlayır. Nəticədə model gələcək oxşar data üçün yalnız pişik və ya it kimi dəyərlər təxmin edə bilər. Pişik və it verilmiş datada cari label‘lar adlanır. Lakin bizdə elə data ola bilər ki, datada label’lar haqqında heç bir məlumat verilməsin. Bu tipdə verilən data isə unlabeled data adlanır.
Supervised Learning
Supervised Learning zamanı labeled olunmuş training datadan istifadə olunur. Belə ki, modelin training datanı öyrənməsi üçün training data X input və Y output/target (label) hissələrinə bölünür.
Model X input və Y output arasında əlaqəni öyrənməyə çalışır. Təbii ki, bu proses seçilmiş modeldən/alqoritmdən/funksiyadan aslıdır. Training üçün verilmiş datanın paylanmasından aslı olaraq ən uyğun funksiyanı seçmək lazımdır. Bu zaman modelin təxmin etdiyi dəyərlər Y output‘una daha yaxın olar. Supervised Learning problemləri Y output/target/label dəyərindən aslı olaraq 2 növə bölünür:
Classification: Əgər Y output dəyəri kateqorikdirsə, onda həll olunmalı problem Classification problem adlanır. Classification problemə misal olaraq, modelin e-poçtun spam olub olmamasını öyrənməsini göstərmək olar. Müxtəlif Classification alqoritmləri mövcuddur. Məsələn, KNN, Logostic Regression, Decision Tree, Random Forest və s.
Regression: Bu zaman isə Y output dəyəri həqiqi ədədlər çoxluğuna daxildir. Regression probleminə misal olaraq, modelin işçinin əmək haqqısını öyrənməsini göstərmək olar. Regression alqoritmlərinə Linear Regression, Decision Tree və s.
Unsupervised Learning
Unsupervised Learning zamanı bizim heç bir output/target/label dəyərimiz yoxdur. Yəni istifadə etdiyimiz data unlabeled datadır. Unlabeled datanın öyrənilməsi (training) zamanı, model özü data daxilindəki informasiyanı qruplaşdırmağa çalışır. Adətən data daxilində nəyi axtarmaq lazım olduğunu bilmədiyimizdə, Unsupervised alqoritmlər istifadə üçün faydalıdır. Unsupervised alqoritmlərə misal olaraq K-means, Hierarchical Clustering göstərmək olar.
Aşağıdakı şəkildən Supervised və Unsupervised Learning alqoritmlərinin fərqini daha yaxşı anlaya bilərik. Bu nümunədə Supervised Learning Classification problemidir və alqoritm şəklin ördək olub-olmamasını öyrənir. Unsupervised Learning halında isə şəkillərdə obyektlərin nə olduğu haqqında heç bir məlumat yoxdur. Bu o deməkdir ki, data unlabeled’dır. Clustering alqoritmi şəkillərdə ortaq xüsusiyyətləri taparaq onları qruplaşdırmağa çalışır. Gördüyümüz kimi alqoritm şəkilləri 3 fərqli çoxluğa bölür.
Semi-supervised Learning
Yuxarıda baxdığımız 2 növ alqoritmlərdə modelin öyrədilməsi zaman ya labeled, ya da unlabeled datadan istifadə olunur. Semi-supervised Learning zamanı isə bu hər iki tip data iştirak edir. Semi-supervised alqoritmlər labeled data miqdarının modelin öyrədilməsi prosesi üçün kifayət olmadığı amma daha çox unlabeled data verildiyi zaman istifadəyə yararlıdır.
Reinforcement Learning
Reinforcement Learning Machine Learning alqoritmlərinin bir növü olduğuna görə, Süni İntellektin (Artificial İntelligence) də bir sahesi hesab edilir. Reinforcement Learning qurğulara müəyyən kontekstdə necə davranmaları lazım olduğunu öyrədir.
Öyrəndiklərimiz
Machine Learning nədir, nə üçün tətbiq olunur.
Modelin öyrədilməsi zamanı istifadə olunan data növlər (training, validation, test data).
Machine Learning alqoritmlərinin növləri (Supervised, Unsupervised, Semi-supervised, Reinforcement Learning )
Növbəti mövzu
Növbəti mövzuda modelin öyrədilməsi zaman istifadə etdiyimiz datanın hansı strukturda olmasından danışacağıq:)